
Mastering Python Lists
by Marc Poulin
Copyright 2015, Marc Poulin
Lesson 1
Introduction
Lists are a powerful feature of Python but most books only scratch the surface. They teach you the basic syntax (the "what") but leave out practical examples (the "why"). This book goes beyond basic syntax and tries to show you the real power of lists.
So why aren't lists more widely used? When you first learn to program, the focus is on individual variables and objects. Lists require you to go beyond that way of thinking and see your data in "chunks" instead.
Many problems are best solved by manipulating lists of data. Python's list operators are a natural fit for these types of problems. They let you write solutions that are both compact and efficient. In short, by learning to "think in lists" you will become a better Python programmer.
Lesson 2
Hello World!
It's customary to start a programming book with a simple "Hello World!" example, and who am I to break with tradition?
greeting = ['Hello', 'World']
This is a "literal" definition of a list. It consists of a comma-separated series of values enclosed in square brackets.
This particular list contains two string values. Lists can contain any type of value, and different types can be mixed together in the same list.
List values can span multiple lines. Here is the same list formatted a bit differently.
greeting = [
'Hello',
'World'
]
TRAILING COMMAS
The last item in a list can be followed by an optional "trailing comma". This comma has no effect, but Python allows it so you don't have to treat the last value differently from the others.
greeting = [
'Hello',
'World', # trailing comma
]
Lesson 3
Empty Lists
We often create empty lists with the intent of filling in the values at a later time.
THE [ ] OPERATOR
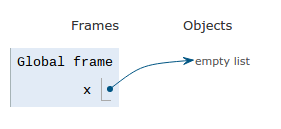
The easiest way to create an empty list is with the list operator [ ].
x = [ ]
THE LIST() FUNCTION
Another way to create an empty list is by calling the list() function with no parameters. The function will return an empty list
x = list()
CREATING A LITERAL LIST OF EMPTY LISTS
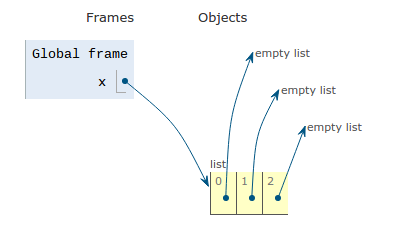
Now we discuss creating a list of empty lists (empty sub-lists). If the number of sub-list is small, we can specify them literally.
x = [
[],
[],
[],
]
CREATING A LIST OF EMPTY LISTS WITH A LIST COMPREHENSION
If the number of sub-lists is large, we can use a list comprehension to generate the list. This reduces the amount of typing we need to do.
x = [[] for i in range(10)]

AVOID USING THE REPEAT OPERATOR
Lists, like other sequence types, support the repeat operator (*). It may be tempting to use the repeat operator to generate a list of empty lists.
This will NOT create distinct sub-lists. Instead, it will create ONE sub-list and fill the main list with multiple references to that ONE list.
x = [ [] ] * 10
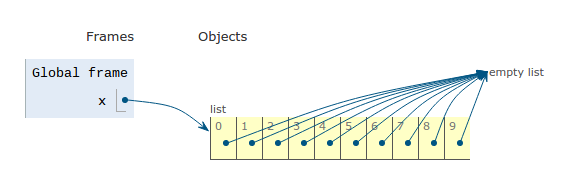
Stop and compare this diagram to the one on the previous page.
Lesson 4
Converting to Other Types
CONVERTING TO A SET
A new set object can be produced from a list by passing the list to the set() function.
Duplicate values are eliminated, so set([1,1,1]) produces {1}.
Order is not preserved, so set([1,2,3,1,1]) might produce {1,2,3}, {1,3,2}, or {2,3,1}.
CONVERTING TO A DICTIONARY
A new dictionary can be produced from a list of (key, value) pairs by passing the list to the dict() function.
dict([('a',1),('b',2),('c',3)]) will produce {'a':1, 'b':2, 'c':3}.
Lesson 5
Unpacking a List
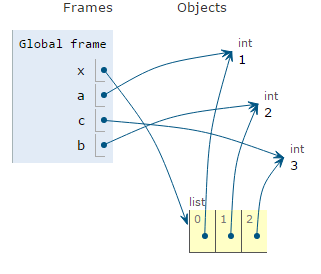
A list can be unpacked into separate variables. This is done with a multiple assignment statement.
x = [1,2,3]
a, b, c = x
UNPACKING IN PYTHON 3.X
In Python 2.x, the number of variables must exactly match the number of values to unpack. Python 3.x relaxes this restriction by adding a starred variable syntax, where the starred variable will contain a (possibly empty) list of values.
The starred variable is used only if the number of list items exceeds the number of unstarred variables.
Note: there can only be one starred variable in the assignment list.
x = [1,2,3]
a, *b = x

In this example, there are enough unstarred variables to account for all the values, so the starred variable contains nothing.
x = [1,2,3]
a, *b, c, d = x
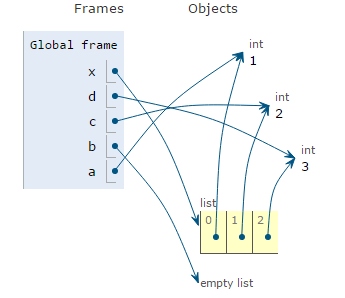
UNPACKING A LIST INTO FUNCTION ARGUMENTS
A list can also be unpacked into function arguments with the "*" operator.
def f(a,b,c):
pass
x = [1,2,3]
f(*x)

Lesson 6
Iterating Over a List
Iteration allows you to retrieve the values from a list one at a time.
ITERABLE OBJECTS
List are iterable, which means they implement Python's iteration protocol. The iteration protocol is based on iterator objects.
Given a list
x = [1,2,3]
You can call the __iter__() method to get an iterator for the list
it = x.__iter__()
The iterator object has a __next__() function, which returns each item in the list one by one.
What happens when there are no more items? The iterator object raises a StopIteration exception to let you know you have reached the end of the sequence.
This is what it looks like in the interactive Python shell:
>>> x = [1,2,3]
>>> it = x.__iter__()
>>> it.__next__()
1
>>> it.__next__()
2
>>> it.__next__()
3
>>> it.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>StopIteration
>>>
ITERATING OVER ALL ITEMS
If you wanted to print all the items in a list, you could use a counter variable to keep track of how many times you should call __next__().
x = [1,2,3]
it = x.__iter__()
count = 0
while count < len(x):
item = it.__next__())
print(item)
count = count + 1
This is how you would loop over a list in other languages like C or Java. Fortunately, Python provides a simpler alternative.
THE FOR STATEMENT
Using raw iterators is very cumbersome and error prone. Python provides a for statement which takes care of all the details of creating the iterator, calling __next__(), and testing for StopIteration.
Here is the same code using a for loop.
x = [1,2,3]
for item in x: # item = x.__next__()
print(item)
WARNING
Do not re-size a list (add or remove items) while you are iterating over it. The iterator keeps an internal count of how many times __next__() has been called and resizing the list will invalidate this count.
THE ENUMERATE FUNCTION
The enumerate function can be used to number items in a list. Numbering starts at 0 by default. This can be useful in cases where you need to know each item's index number. The return value is a list containing (number, item) pairs.
Given
x = ['a', 'b', 'c']
enumerate(x) produces
[(0,'a'), (1,'b'), (2,'c')]
Do you need to know the index value of each item? You can use enumerate in a for statement instead of a counter variable.
for index, value in enumerate(x):
Lesson 7
Copying a List
THE LIST() FUNCTION
The built in list() function will produce a list from any iterable object. Since lists are iterable objects, we can use list() to make a copy.
It's important to remember that copying a list does not create new objects. Copying simply creates additional references to the existing objects.
x = ["Hello","World"]
y = list(x)
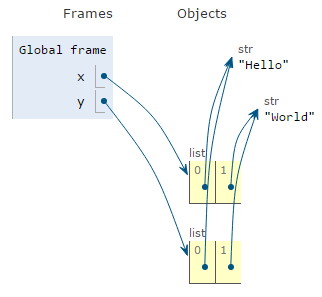
Although we speak of lists "containing" values, this is not strictly true. Lists contain "references" to objects, not the objects themselves. In the previous figure you see arrows leading away from the lists to the strings. Those arrows represent references to the string objects.
THE COPY() FUNCTION
You can import the copy() from the copy module and use it to copy a list. This is a general-purpose function that be used to copy any object.
from copy import copy
x = [1,2,3]
y = copy(x)
SLICING
Slicing a list is a third way of making a copy. We will talk about this in the Slicing lesson.
Lesson 8
Subscripts
Each list item occupies a specific position. Positions are numbered starting at 0 and each item can be referenced by it's position number (called the "index"). We subscript a list by writing the index number in square brackets after the list.
list[index]
Here is a diagram of the "greeting" list in Lesson 2.
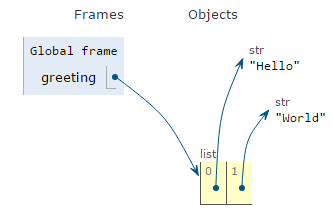
greeting[0] refers to the string object 'Hello'
greeting[1] refers to the string object 'World'
Lesson 9
Negative Subscripts
For convenience, Python allows both positive and negative subscripts.
Normal Python subscripts (like subscripts in most other languages) start at 0 and are relative to the start of the list.
[0] [1] [2] # positive
x = ['a', 'b', 'c']
But subscripts can also be specified from the end of the list using negative indexes.
[0] [1] [2] # positive
x = ['a', 'b', 'c']
[-3] [-2] [-1] # negative
This means the first item can always be accessed as x[0] and the last item can always be accessed as x[-1], even without knowing the length of the list.
Alternatively (and in other languages that don't support negative subscripts) you could compute the last index as
x[len(x)-1]
This is slower (requiring a function call), longer to type, harder to read, and more prone to errors.
CONVERSION FORMULAS
You can easily convert between positive and negative subscripts if you know the length of the list.
Let P be the positive index,
N be the negative index, and
L be the list length.
Then
P = L + N # converting a known negative to a positive
and
N = P - L # converting a known positive to a negative
Lesson 10
Ranges
In Python 2.x, the range() and xrange() functions can be used to produce a list of numbers in either ascending or descending order.
NOTE: in Python 3.x, the xrange() function has been renamed to range().
PARAMETERS
The range(start, stop, step) function takes 3 parameters.
start - the first number of the range (optional, defaults to 0)
stop - the last number of the range (not included in the result)
step - controls ascending/descending and the interval between numbers (optional, defaults to +1).
The step can be positive or negative. If step > 0, numbers are produced by counting UP from start to stop (not including stop). If step < 0, numbers are produced by counting DOWN from start to stop (not including stop).
The step can also skip over values. If step = 2, the output contains every 2nd value, if step = 3, the output contains every 3rd value, etc.
The xrange (Python 2.x) and range ( Python 3.x) functions return iterator objects. Use the list() function to turn the iteration into an actual list.
x = list(xrange(5))
EXAMPLES
Here are some examples of the range() function with various start, stop, and end values.
REMEMBER: the stop value is always excluded from the result.
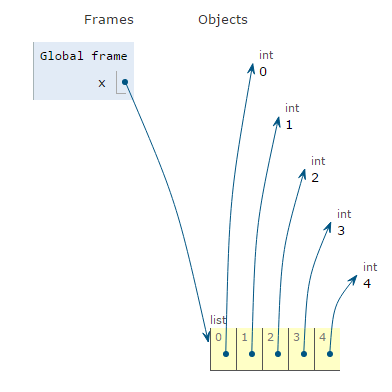
x = range(5) # Python 2.x
x = list(range(5)) # Python 3.x
x = range(3, 5) # Python 2.x
x = list(range(3, 5)) # Python 3.x

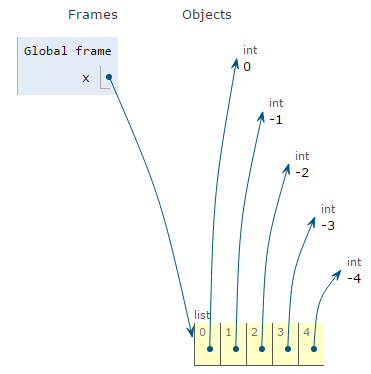
x = range(0, -5, -1) # Python 2.x
x = list(range(0, -5, -1)) # Python 3.x
Lesson 11
Range Slices
Range slices are new feature of Python 3.x. Understanding range slices will prepare us to look at list slices in Lesson 14.
Syntax — [start : end : stride]
The slice syntax is similar to the subscripting syntax (they both use square brackets). A slice is specified with 3 parameters, all of which are optional. The parameters are separated by a ":" character.
start - the start of the range to copy
end - the end of the range to copy.
stride - the direction in which copying takes place and the number of items to skip over.
REMEMBER: the end value is always excluded from the result.
The start, end, and stride parameters all have default values.
start - defaults to the first item in the list
end - defaults to everything after the start (including the last item)
stride - defaults to 1
Lesson 12
Forward Range Slices
Slicing a range object produces another range object. This second range object will generate the desired values.
By examining these slice objects in the Python shell we can see how the start, end, and stride values are being interpreted.
WITH POSITIVE PARAMETERS
Positive start and end values are relative to the beginning of the range.
# The full range
>>> x = range(5)
>>> x
range(0, 5)
>>> list(x)
[0, 1, 2, 3, 4]
# All values from the first to the last
>>> x[::]
range(0, 5)
>>> list(x[::])
[0, 1, 2, 3, 4]
# All values from x[2] to the last
>>> x[2::]
range(2, 5)
>>> list(x[2::])
[2, 3, 4]
# All values from x[2] up to but not including x[4]
>>> x[2:4]
range(2, 4)
>>> list(x[2:4:])
[2, 3]
# All values from x[1] to the last, skipping every other value
>>> x[1::2]
range(1, 5, 2)
>>> list(x[1::2])
[1, 3]
This table summarizes the results
Slice
|
Equivalent Range
|
Produces
|
x[::]
|
range(0, 5)
|
[0, 1, 2, 3, 4]
|
x[2::]
|
range(2, 5)
|
[2, 3, 4]
|
x[2:4]
|
range(2, 4)
|
[2, 3]
|
x[1::2]
|
range(1, 5, 2)
|
[1, 3]
|
WITH NEGATIVE PARAMETERS
Earlier, we saw how negative list indexes are relative to the end of the list. Similarly, negative start and end values are relative to the end of the range.
Spend some time studying these examples to make sure you really understand what's going on. Notice how Python converts negative values to their positive equivalents.
# The full range
>>> x = range(5)
>>> x
range(0, 5)
>>> list(x)
[0, 1, 2, 3, 4]
# All the value from x[-2] to the last
>>> x[-2::]
range(3, 5)
>>> list(x[-2::])
[3, 4]
# The values from x[-2] up to but not including x[-1]
>>> x[-2:-1:]
range(3, 4)
>>> list(x[-2:-1:])
[3]
# All the values from x[-4] to the last, skipping every other value
>>> x[-4::2]
range(1, 5, 2)
>>> list(x[-4::2])
[1, 3]
Slice
|
Equivalent Range
|
Produces
|
x[-2::]
|
range(3, 5)
|
[3, 4]
|
x[-2:-1:]
|
range(3, 4)
|
[3]
|
x[-4::2]
|
range(1, 5, 2)
|
[1, 3]
|
Lesson 13
Reverse Range Slices
A negative step value will produce a reverse slice. In a reverse slice, the values are produced by counting down from the start to the end.
WITH POSITIVE PARAMETERS
Positive start and end values are relative to the beginning of the range.
# The full range
>>> x = range(5)
>>> x
range(0, 5)
>>> list(x)
[0, 1, 2, 3, 4]
# All values from the last to the first
>>> x[::-1]
range(4, -1, -1)
>>> list(x[::-1])
[4, 3, 2, 1, 0]
# All values from x[2] to the first
>>> x[2::-1]
range(2, -1, -1)
>>> list(x[2::-1])
[2, 1, 0]
# All values from x[4] down to but not including x[2]
>>> x[4:2:-1]
range(4, 2, -1)
>>> list(x[4:2:-1])
[4, 3]
# All values from x[4] to the first, skipping every other value
>>> x[4::-2]
range(4, -1, -2)
>>> list(x[4::-2])
[4, 2, 0]
Slice
|
Equivalent Range
|
Produces
|
x[::-1]
|
range(4, -1, -1)
|
[4, 3, 2, 1, 0]
|
x[2::-1]
|
range(2, -1, -1)
|
[2, 1, 0]
|
x[4:2:-1]
|
range(4, 2, -1)
|
[4, 3]
|
x[4::-2]
|
range(4, -1, -2)
|
[4, 2, 0]
|
WITH NEGATIVE PARAMETERS
Negative start and end values are relative to the end of the range.
# The full range
>>> x = range(5)
>>> x
range(0, 5)
>>> list(x)
[0, 1, 2, 3, 4]
# All the values from x[-2] down to the first
>>> x[-2::-1]
range(3, -1, -1)
>>> list(x[-2::-1])
[3, 2, 1, 0]
# The values from x[-1] down to but not including x[-2]
>>> x[-1:-2:-1]
range(4, 3, -1)
>>> list(x[-1:-2:-1])
[4]
# All the values from x[-4] down to the first, skipping every other value
>>> x[-1::-2]
range(4, -1, -2)
>>> list(x[-1::-2])
[4, 2, 0]
Slice
|
Equivalent Range
|
Produces
|
x[-2::-1]
|
range(3, -1, -1)
|
[3, 2, 1, 0]
|
x[-1:-2:-1]
|
range(4, 3, -1)
|
[4]
|
x[-1::-2]
|
range(4, -1, -2)
|
[4, 2, 0]
|
Lesson 14
List Slices
Now that we've looked at range slices, we are ready to talk about list slices.
The slice operator specifies a range of list indexes. Items from this range are copied from the original list into a new list object.
Although this lesson is about lists, you should know that slicing can also be applied to strings, tuples, and (in 3.x) ranges.
SLICE SYNTAX
Syntax — [start : end : stride]
The slice syntax is similar to the subscripting syntax (they both use square brackets). A slice is specified with 3 parameters, all of which are optional. The parameters are separated by a ":" character.
start - the start of the range to copy
end - the end of the range to copy.
stride - the direction in which copying takes place and the number of items to skip over.
REMEMBER: the end value is always excluded from the result
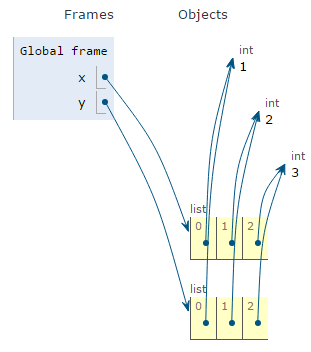
QUICK COPY
Using the default values for start, end, and stride will copy every item in the list. This is a quick alternative to using either the copy() or list() functions.
x = [1,2,3]
y = x[::]
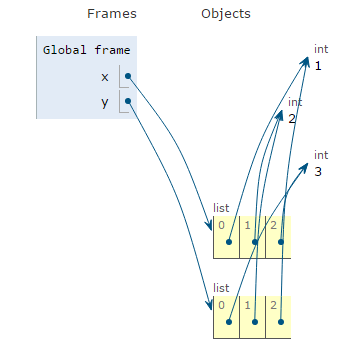
QUICK REVERSED COPY
Using a stride of -1 with default start and end values will produce a reversed copy.
x = [1,2,3]
y = x[::-1]
Lesson 15
Forward List Slices
A forward slice copies everything from the start index up to (not including) the end index.
Using a stride > 0 (or letting the stride value default) will produce a forward slice.
x = [1,2,3]
y = x[0:2:1]
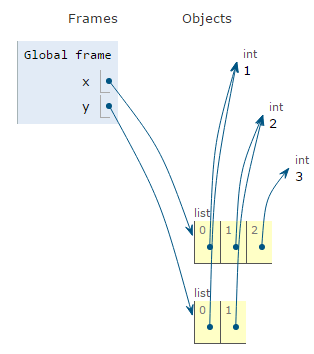
Notice that x[2] is not copied into y.
DEFAULT VALUES
The start, end, and stride parameters have default values.
start - defaults to the first item in the list
end - defaults to everything after the start (including the last item)
stride - defaults to 1
Note that a default end value [::1] is not the same as specifying the last item [:-1:1]. In the first case ([::1]) the last item is include in the slice, while in the second case ([:-1:1]) it is not.
SKIPPING ITEMS
Using a stride > 1 will skip values. A stride of 2 will copy every 2nd value, a stride of 3 will copy every 3rd value, and so forth.
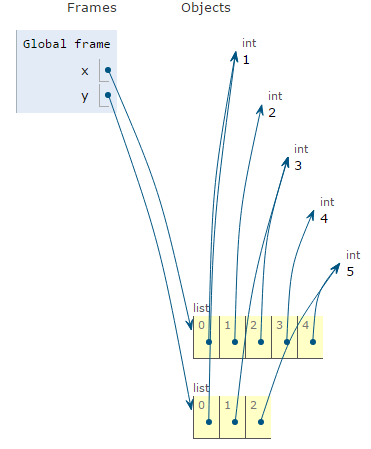
x = [1,2,3,4,5]
y = x[::2]
Lesson 16
Reverse List Slices
Specifying a stride < 0 will produce a reverse slice. Items are copied backwards from the start down to the end.
DEFAULT VALUES
The start and end parameters both have default values.
start - defaults to the last item of the list.
end - defaults to everything ahead of the start (including the first item)
There is no default stride. If you want a reverse slice you must specify a negative stride explicitly.
Remember, using a default end value is not the same as specifying an end value of 0. In the first case ([-1::-1]) item [0] is included in the slice, while in the second case ([-1:0:-1]) it is not.
Lesson 17
List Comprehensions
List comprehensions combine list syntax, for statement syntax, and if statement syntax into one statement. They look complicated because they combine a lot of different syntax into one statement. But don't worry — everything you know about for and if statements still applies.
The syntax of a list comprehension consists of 3 parts enclosed in square brackets.
[output-clause for-clause if-clause]
It works by iterating over an input list (the for clause), testing the values (the if-clause), and computing an output value (the output-clause). It is equivalent to
destination_list = []
for i in source_list:
if (if_clause(i)):
destination_list.append(output_clause(i))
Given a list of strings, how would you create a new list that contains (string, len(string)) tuples? Specifically, how would you transform ['Hello', 'World'] into [('Hello', 5), ('World', 5)]?
Here is a solution using an explicit for loop:
words = ['Hello', 'World']
output = []
for word in words:
output.append((word, len(word)))
And here is the equivalent logic using a list comprehension
words = ['Hello', 'World']
output = [(word, len(word)) for word in words]
The comprehension takes care of creating a new list object and inserting the calculated values into the new list (without using the append method), all in one line of code.
VARIABLES BEHAVE DIFFERENTLY IN 2.X AND 3.X
Variables behave differently in Python 2.x and 3.x. In Python 2.x, any variables created inside the comprehension continue to exist outside the comprehension. In Python 3.x, variables inside the comprehension are private.
x = [1,2,3]
x_squares = [i*i for i in x]
print(i) # prints 3 (2.x)
# NameError exception (3.x)
Lesson 18
Boolean Operations
IF AND WHILE STATEMENTS
We often need to determine whether or not a list is empty. Since this is such a common situation, Python provides a simplified syntax for testing this. In an if or while statement, a list variable evaluates to False when the list is empty and True when it is not.
if len(x)>0: can be written if x:
while len(x)>0: can be written while x:
THE ANY() AND ALL() FUNCTIONS
These two built-in functions return a logical True or False based on the contents of a list.
The all() function performs a logical AND across all the items in list. It returns True if all the items evaluate to True.
The any() function performs a logical OR across all the items in a list. It returns True if at least one item evaluates to True.
You can use the logical not operator in combination with any() and all() to test for other variations.
To summarize:
all() — True if every value is True
not any() — True if every value is False
any() — True if at least 1 value is True
not all() — True if at least 1 value is False
The any() and all() functions can be nested to form AND/OR tables (decision tables). These can be used instead of if statements to encode complex business logic.
For example, consider what happens when you make a withdrawal from a bank account. The bank needs to look at your account balance, the withdrawal amount, and any overdraft line of credit that might be available.
approved = any(
all(balance >= amount),
all(balance < amount, available_credit > amount)),
)
if approved:
# process withdrawal
This is just a simple example. A real application might need to consider dozens of rules and complex relationships between them.
Lesson 19
Processing Multiple Lists
PROCESSING LISTS IN SERIES
The obvious way to process lists sequentially is to concatenate them with the "+" operator. This has the effect of combining all the lists into a single list.
x = [1,2,3]
y = [4,5,6]
for i in x+y:
print(i)
This will print
1
2
3
4
5
6
Concatenation requires copying the lists. This can be inefficient if the lists are large. The itertools module provides a chain function. It has the same effect as the "+" operator but the lists are not copied.
import itertools
for i in itertools.chain(x,y):
print(i)
print(i)
THE ZIP() FUNCTION
The zip function combines multiple lists in parallel by collecting all the items at each position into a single tuple.
For example, if you have two lists
a = [1,2,3]
b = ['a','b','c']
The result of zip(a,b) would be
[
(a[0], b[0]),
(a[1], b[1]),
(a[2], b[2]),
]
This is useful if you want to iterate over multiple lists at the same time without using a counter variable.
Let's look at another example. Given a list of cities and a list of countries, how would you print each city/country pair?
cities = ['Madrid', 'Rome', 'Paris']
countries = ['Spain', 'Italy', 'France']
Without zip, you would need three things:
- a counter variable to keep track of where you are in the iteration
- a call to the range() function to generate the subscript values
- a subscript on each list to retrieve the values
Your code might look like this
for i in range(len()):
city = cities[i]
country = countries[i]
print(city, country)
This might look familiar if you have experience in other programming languages.
Using zip, your code would look like this:
for city,country in zip(cities,countries):
print(city, country)
How this works:
- zip produces a list of tuples
- the for statement iterates over the tuples
- each tuple is unpacked into the city and country variables
UNZIPPING
There is no unzip() function, but you can achieve the same result with the "*" operator.
Given
z = zip(a, b, c)
you can use
a, b, c = zip(*z)
to recover the original lists.
TRANSPOSING A MATRIX
The zip function can also be used to extract individual columns from a matrix, or to transpose the entire matrix.
Given a 3x3 matrix
[
[1,2,3],
[4,5,6],
[7,8,9],
]
the transpose would be
[
[1,4,7],
[2,5,8],
[3,6,9],
]
The rows become columns and the columns become rows.
If you have a 2 dimensional matrix like
x = [
[1,2,3],
[4,5,6],
[7,8,9],
]
It's easy to access the rows. But how do you extract the columns?
One way is with nested for loops.
ROWS = len(x)
COLUMNS = len(x[0])
x_transpose = []
for column in range(COLUMNS):
r = []
for row in range(ROWS):
r.append(x[row][column])
x_transpose.append(r)
Another way is to flatten the matrix and slice out the columns.
x_transpose = []
values = []
for row in x:
values.extend(row)
# values contains [1,2,3,4,5,6,7,8,9]
for column in COLUMNS:
x_transpose.append(x[column::COLUMNS])
But the easiest way is to use zip.
x_transpose = zip(*x)
The secret is the "*" operator, which unpacks the matrix and passes the individual rows to zip.
zip(*x)
is equivalent to zip(x[0], x[1], x[2])
which is equivalent to zip([1,2,3], [4,5,6], [7,8,9])
which outputs [(1,4,7), (2,5,8), (3,6,9)]
TIC TAC TOE
I assume you are familiar with the game tic-tac-toe.
If you are programming this game, one problem you need to solve is how to check for a winner. Here is one approach.
Assume the board is a 3x3 matrix of X's and O's like
board = [
['x', '', 'x'],
['', 'o', ''],
['', 'o', '']
]
A player wins if any row, column, or diagonal contains all X's or all O's. Here's one possible implementation. The secret is in setting up the list. Once that's done, you can determine the winner with a single line of code.
def is_winner(player):
'''
Return true if player is a winner.
Player can be "x" or "o".
Iterate over all the rows, columns, and
diagonals. Return true if the player
appears 3 times in any row, column, or
diagonal.
'''
#
start with the rows
x
= board
#
next, add the columns
x.extend(zip(*board))
#
finally, add the diagonals
diagonals
= [
[board[0][0],
board[1][1], board[2][2]],
[board[2][0],
board[1][1], board[0][2]],
]
x.extend(diagonals)
#
verify that x contains the right number of items
assert
len(x) == 8
#
determine if 'player' is a winner
#
check every row, column, and diagonal
return
any([i.count(player)==3 for i in x])
Lesson 20
Sorting
You can sort a list by either sorting it in-place or by creating a sorted copy of the original list
SORTING IN-PLACE
The sort() method sorts a list in-place. The original order of the items is lost.
x = [3,2,1]
x.sort()
x now contains [1,2,3]
CREATING A SORTED COPY
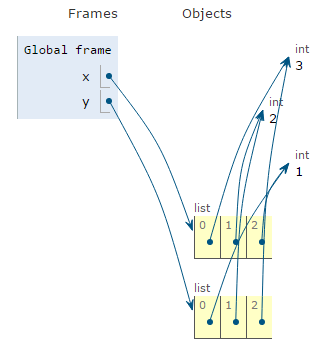
You can use the sorted() function to create a sorted copy of the original list.
x = [3,2,1]
y = sorted(x)
REVERSE SORT
Both the sort() method and the sorted() function take an optional reverse parameter. The list is sorted in reverse order if reverse=True.
SPECIFYING A SORT KEY
Normally, list items are sorted by comparing their values. This means numbers are sorted numerically and strings are sorted alphabetically.
The optional key parameter let's you define your own comparison function. This lets you sort items by any attribute, either built-in or computed.
Here is a default string sort. Normally, upper case sort before lower case.
>>> x = ['a', 'b', 'C', 'd']
>>> sorted(x)
['C', 'a', 'b', 'd']
Here is a case insensitive sort. The strings are converted to lower case before being compared.
>>> sorted(x, key=string.lower)
['a', 'b', 'C', 'd']
IMPORTANT: the key values are only used internally by the sort function. They do not appear in the output.
LAMBDA FUNCTIONS
Key functions are often written using lambda expressions. You can learn more about them at
Here is an example of sorting numbers by their absolute value. The key is defined with a lambda expression.
>>> x = [1, 2, -1, 0]
>>> sorted(x, key=lambda i:abs(i))
[0, 1, -1, 2]
Lesson 21
Adding Items To A List
There are several ways to add items to a list
ADDING ONE ITEM TO THE END
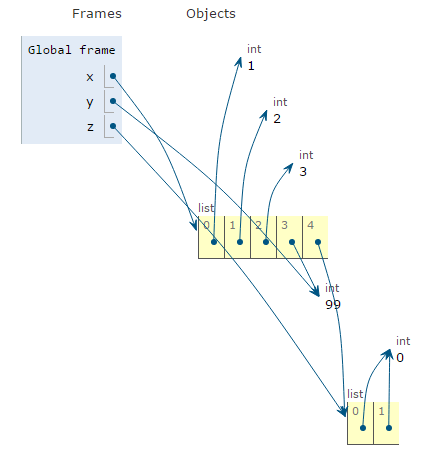
The append() method adds a single item to the end of a list. If the item contains multiple values (like a list or a tuple) the whole item is added.
x = [1,2,3]
y = 99
z = [0,0]
x.append(y)
x.append(z)
Notice how x[4] refers to the entire "z" list.
EXTENDING A LIST
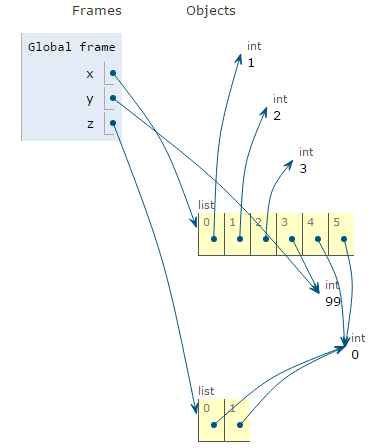
The extend method works by iterating over an object and appending the values one by one.
x = [1,2,3]
y = 99
z = [0,0]
x.append(y)
x.extend(z)
Notice how the "z" list has been unpacked so that x[4] and x[5] now refer to z[0] and z[1].
NOTE: the parameter passed to extend() must be iterable.
ADDING ONE ITEM IN THE MIDDLE
The insert method will insert one new item ahead of an existing item.
x = [1,2,3]
index = 0
x.insert(index, 0)
x now contains [0,1,2,3]
Inserting into an empty list acts like append().
>>> x = []
>>> x.insert(99, 'a')
>>> print(x)
'a'
ADDING MULTIPLE ITEMS IN THE MIDDLE
Slice notation can be used to insert multiple values ahead of an existing item.
>>> x = [1,2,3]
>>> x[1:1] = ['a','b','c']
>>> print(x)
[1, 'a', 'b', 'c', 2, 3]
Lesson 22
Removing Items From a List
REMOVING AN ITEM BY INDEX
Use either the del keyword or the pop() method if you know the index of the item you want to remove.
REMEMBER: del is a keyword, not a function.
>>> x = ['a', 'b', 'c']
>>> del x[1]
>>> print(x)
['a', 'c']
>>> x = ['a', 'b', 'c']
>>> x.pop(1)
>>> print(x)
['a', 'c']
REMOVING ONE OR MORE ITEMS BY VALUE
The remove() method removes the first occurrence of an item from a list. Use a list comprehension filter if you want to remove all occurrences.
x = [1,2,3,2,1,2]
filtered_list = [i for i in x if i != 2]
will delete all occurrences of the number 2.
Lesson 23
Reversing a List
REVERSE METHOD
The reverse() method performs an in-place reversal.
x = [1,2,3]
x.reverse()
x now contains [3,2,1]
NOTE: the reverse() method modifies the original list. Use the reversed() function if you want to preserve the order of the list.
REVERSED FUNCTION
The reversed() function (spelled with a "d") returns an iterator object that will produce the items in reverse order. Use the list() function to create an actual list of values.
x = [1,2,3]
y = reversed(x)
y_list = list(y)
Lesson 24
Removing Duplicate Values
REMOVING DUPLICATES WITHOUT PRESERVING ORDER
You know that converting a list to a set will remove any duplicate values. We can use that fact to quickly remove duplicates if order is not important.
x = [1,2,1,2,3]
x = list(set(x))
REMOVING DUPLICATES WHILE PRESERVING ORDER
There's no built-in function for doing this, but the code is not too hard to write. You just need to keep track of the values you've already seen.
x = [1,2,1,2,3,1]
not_seen = set(x)
unique_list = []
for value in x:
# is this a value we haven't seen yet?
if value in not_seen:
unique_list.append(value)
not_seen.remove(value)
# has every value been seen?
if not not_seen:
break
Lesson 25
Searching for Values
TESTING FOR THE PRESENCE OF AN ITEM
Use the in operator to test for the presence of an item.
Given a list 'x'
item in x
returns True if 'item' appears in x at least once.
Or you can use the count method
x.count(item)>0
NOTE: the 'in' operator is more efficient. It returns as soon as a match is found. The count method will always process the entire list.
FINDING THE INDEX OF AN ITEM
Use the index() method if you need to know the position of an item.
Given a list 'x'
x.index(item)
returns the index of the item. A ValueError exception is raised if x does not contain the item.
FINDING THE INDEXES OF DUPLICATES
If 'item' appears in a list more than once and you need to know the index of every instance, use enumerate() with a list comprehension.
Given a list 'x'
item_indexes = [i for i,j in enumerate(x) if j == item]
FINDING THE LARGEST OR SMALLEST VALUE
Use the max() and min() functions to find the largest or smallest item in a list.
FINDING THE INDEX OF THE LARGEST OR SMALLEST VALUE
The max() and min() functions take an optional key parameter. The key specifies the value to use when comparing objects.
To find the index of the largest item, first use enumerate to pair each item with its index. Then call max() and use the key to compare the values while ignoring the indexes.
pairs = enumerate(x)
index, value = max(pairs, key=lambda pair:pair[1])
You can write this in one line if you like.
index, value = max(enumerate(x), key=lambda pair:pair[1])
Lesson 26
Counting Values
Use len() to count the total number of items in a list. An empty list has a length of 0.
THE COUNT() METHOD
Lists have a count() method. This method counts the total number of times a specified value appears in the list.
x = [1,2,3,1,2,1]
x.count(1) equals 3
THE COUNTER CLASS
The count() method is not very efficient if you want to count every item in a list because you need to count the items individually.
x = [1,2,3,1,2,1]
items = set(x)
for item in items:
x.count(item)
In this situation the collections.Counter class is a better choice. The Counter object creates a dictionary containing an {item:count} entry for each item. The items can be used as dictionary keys to retrieve the counts.
from collections import Counter
x = ['a', 'b', 'a']
counter = Counter(x)
The variable counter now contains {'a':2, 'b':1} and counter['a'] returns 2.
Counters can be added together to accumulate counts. Here the counts from y are added to the previous counts from x.
y = ['a', 'b', 'c', 'd']
counter += Counter(y)
Counters can also be used to analyze text. Given a string named 'text', Counter(text.split()) will split the string into a list of words and count the number of times each word appears.
No comments:
Post a Comment